오디오 파형을 보여주기 위해서 사용했던 Wavesurfer.js 는 다 좋은데 너무 느렸다. 하나의 오디오 파일을 그려주는 것 까지는 나쁘지 않은데 두 개만 동시에 보여주려고 해도 급격히 느려지는 현상이 발생했다. 안그래도 느린 내 노트북으로는 감당하기가 너무 힘들기도 하고 파일이 많아지면 페이지 로딩 자체가 점점 더 많이 느려질 것 같아서 이걸 개선해보기로 했다.
Wavesurfer.js 의 exportImage() 메서드
페이지에 Wavesurfer.js 를 박아 놓으면 매번 페이지가 로딩될 때마다 waveform 이미지를 새로 그려서 보여주게 된다.
페이지가 로딩되면 S3에 있는 오디오 파일을 불러와서 load() 메서드에 전달하고 그때부터 이미지를 그리기 시작해서 다 그려지면 보여주게 되는데 이게 대략 1초 ~ 2초 사이가 걸리는 것 같다.
그래서 매번 새로 이미지를 그려주지 말고 한 번 그린 이미지를 가지고 있도록 할 수 없을까 하는 생각이 들었다. 그래서 관련 메서드가 있는지 찾아보던 중 exportPCM() 이라는 메서드가 있는 것을 발견했다.
Pulse-code Modulation, PCM
펄스 부호 변조(Pulse-code modulation, 줄여서 PCM)는 아날로그 신호의 디지털 표현으로, 신호 등급을 균일한 주기로 표본화한 다음 디지털 (이진) 코드로 양자화 처리된다. PCM은 디지털 전화 시스템에 쓰이며, 컴퓨터와 CD 레드북에서 디지털 오디오의 표준이기도 하다. 또, 이를테면 ITU-R BT.601을 사용할 때 디지털 비디오의 표준이기도 하다. 그러나 직접적인 PCM은 DVD, 디지털 비디오 레코더와 같은 소비자 수준의 SD 비디오에서 쓰이지 않는다. (왜냐하면 요구되는 비트 속도가 너무 높기 때문이다.) 일반적으로 PCM 인코딩은 직렬 형태의 디지털 전송에 자주 쓰인다.
출처: 위키피디아
PCM이 뭔지 찾아보니 이런거라고 한다. 대략 오디오 파일의 신호를 디지털 신호로 바꾼 값인 것 같은데 exportPCM() 을 실행해보니 아래와 같이 null 값들의 어레이가 생성되었다.
[null, null, null, null, ... null, 0, 0]
마지막 두개는 0인데 왜이러는 건지도 모르겠고 왜 null 값이 잔뜩 오는지도 모르겠다. 요소 개수가 파형을 만들 때 지정했던 막대 개수와 같은 것을 보니 각 막대의 렌더링에 사용되는 그런 값인것 같지만 작동법을 제대로 몰라서 그런건지 결과적으로 작동을 하지 않았다.
이것 저것 계속 시도해보다가 답답한 마음에 그냥 이미지를 추출해주는 메서드는 없을까…하면서 exportImage() 라고 실행해보았는데 어이가 없게도 파형을 그리는데 사용된 이미지가 추출이 되었다…
문서 어디어도 저런 메서드가 있다고 쓰여있지 않지만 잘 작동했다.
아래는 exportImage() 로 얻어진 파형 이미지이다.
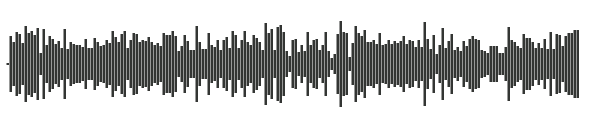
그런데 생각해보면 이 이미지를 얻기 위해서는 load() 메서드를 통해서 파형이 먼저 완성이 되어야하는데 그렇다면 이 이미지를 가져와서 다시 사용하려면 미리 파형을 그린다음 그 이미지를 저장하고 있어야한다. 그 저장 시점은 최초로 음원 파일이 업로드되는 시점이되어야 할 것이다.
그럼 이미 업로드된 음원 파일들에 대해서는 파형 이미지를 어떻게 그려줄지 생각을 하다가 그냥 처음부터 서버에서 Python 으로 그려줄 수 있으면 좋겠다는 생각이 들었다. 그러면 이미 업로드된 파일들에 대해서도 동일한 Python 코드를 실행시켜서 파형 이미지를 그려줄 수 있기 때문이다.
Python 으로 오디오 파일 파형 그리기
Python 으로 오디오 파일의 파형을 직접 그려주는 코드를 짜보려고 했으나 시간이 너무 오래 걸릴 것 같아서 미리 작성되어 있는 코드를 찾아보기로 했다. 그 결과 아래의 코드를 찾게 되었다.
참고자료: waveformpy_mixxorz_python
import sys
from pydub import AudioSegment
from PIL import Image, ImageDraw
class Waveform(object):
bar_count = 150
db_ceiling = 60
def __init__(self, filename):
self.filename = filename
audio_file = AudioSegment.from_file(
self.filename, self.filename.split('.')[-1])
self.peaks = self._calculate_peaks(audio_file)
def _calculate_peaks(self, audio_file):
""" Returns a list of audio level peaks """
chunk_length = len(audio_file) / self.bar_count
loudness_of_chunks = [
audio_file[i * chunk_length: (i + 1) * chunk_length].rms
for i in range(self.bar_count)]
max_rms = max(loudness_of_chunks) * 1.00
return [int((loudness / max_rms) * self.db_ceiling)
for loudness in loudness_of_chunks]
def _get_bar_image(self, size, fill):
""" Returns an image of a bar. """
bar = Image.new('RGBA', size, fill)
return bar
def _generate_waveform_image(self):
""" Returns the full waveform image """
bar_width = 4
px_between_bars = 1
offset_left = 4
offset_top = 4
width = ((bar_width + px_between_bars) * self.bar_count) + (offset_left * 2)
height = (self.db_ceiling + offset_top) * 2
im = Image.new('RGBA', (width, height), '#ffffff00')
for index, value in enumerate(self.peaks, start=0):
column = index * (bar_width + px_between_bars) + offset_left
upper_endpoint = (self.db_ceiling - value) + offset_top
im.paste(self._get_bar_image((bar_width, value * 2), '#333533'),
(column, upper_endpoint))
def save(self):
""" Save the waveform as an image """
png_filename = self.filename.replace(
self.filename.split('.')[-1], 'png')
with open(png_filename, 'wb') as imfile:
self._generate_waveform_image().save(imfile, 'PNG')
return png_filename
하나씩 살펴보자.
Class Attribute
class Waveform(object):
bar_count = 150
db_ceiling = 60
먼저 Waveform 클래스의 속성을 살펴보면 다음과 같다.
bar_count: 음원 파형을 그리는데 사용할 총 막대기 개수db_ceiling: 음원 파형들의 높이를 평준화(normalize) 시키는 값
__init__
def __init__(self, filename):
self.filename = filename
audio_file = AudioSegment.from_file(
self.filename, self.filename.split('.')[-1])
self.peaks = self._calculate_peaks(audio_file)
다음으로 __init__ 을 살펴보자.
self.filename: 인스턴스화 될 때, 오디오 파일의 위치를 받는다.audio_file:self.filename으로 받은 오디오 파일으로AudioSegment객체를 생성한다.AudioSegment객체는from_file()메서드로 생성되며 이 메서드는 첫 번째 인자로오디오 파일 위치를, 두 번째 인자로파일 확장자를 받는다.self.peaks: 각 오디오 파형 막대의 높이를 계산할 때 사용될 볼륨 피크 값으로_calculate_peaks()메서드로 계산되는 어레이 데이터이다.
구간별 볼륨값 데이터를 계산하는 메서드
_calculate_peaks() 메서드는 각각의 파형 막대의 높이를 계산하는데 쓰이는 볼륨값 데이터를 리스트로 리턴하는 메서드이다.
def _calculate_peaks(self, audio_file):
""" Returns a list of audio level peaks """
# 음원 파일의 길이를 막대의 개수로 나누어서 막대 하나가 나타내게 될 음원의 부분 길이를 계산한다.
chunk_length = len(audio_file) / self.bar_count
# 오디오 파일을 막대의 개수로 나눈 길이 만큼씩 순회하면서 그 부분의 소리 크기(rms) 값을 리스트에 저장한다.
loudness_of_chunks = [
audio_file[i * chunk_length: (i + 1) * chunk_length].rms
for i in range(self.bar_count)]
# 구해진 리스트에서 가장 큰 값을 max_rms 값에 저장한다.
# 1.00 을 곱하여 float 값으로 바꿔준다.
max_rms = max(loudness_of_chunks) * 1.00
# 각 막대의 rms 값을 최대 rms 값으로 나누어 최대값에 대한 비율로 바꿔주고
# 거기에 다시 db_ceiling 값을 곱해 평준화 시켜준다음 정수로 변환한다.
return [int((loudness / max_rms) * self.db_ceiling)
for loudness in loudness_of_chunks]
막대 이미지를 그리는 메서드
Python 에서 이미지를 다루는데 사용하는 Pillow 패키지를 사용하여 각각의 파형 막대를 그려주는 메서드이다.
def _get_bar_image(self, size, fill):
""" Returns an image of a bar. """
# 크기 값과 색상 값을 받아서 막대 이미지를 생성하고 리턴한다.
bar = Image.new('RGBA', size, fill)
return bar
막대 이미지들을 합치는 메서드
그려진 각각의 막대 이미지들을 하나의 큰 이미지에 이어 붙여 그려준다.
def _generate_waveform_image(self):
""" Returns the full waveform image """
bar_width = 4 # 막대 하나의 넓이
px_between_bars = 1 # 막대 사이의 간격
offset_left = 4 # 왼쪽 여백
offset_top = 4 # 위쪽 여백
# 전체 넓이 = (막내 하나 넓이 + 막대 사이 간격) * 막대 개수 + (왼쪽 여백 * 2)
width = ((bar_width + px_between_bars) * self.bar_count) + (offset_left * 2)
# 전체 높이 = (db_ceiling 값 + 위쪽 여백) * 2
height = (self.db_ceiling + offset_top) * 2
# 전체 넓이와 전체 높이를 가지는 비어있는 이미지 생성
im = Image.new('RGBA', (width, height), '#ffffff00')
# self.peaks의 각 요소를 하나씩 순회하면서
for index, value in enumerate(self.peaks, start=0):
# 막대를 붙여넣기 할 X 축 위치 지정
# 매 (막대 넓이 + 막대 간격)값, 즉, 5px, 10px, 15px... 마다 막대를 붙여넣기 한다.
# offset_left 값만큼 떨어진 위치에서 각각 실행됨. 즉, 9px, 14px, 19px...
column = index * (bar_width + px_between_bars) + offset_left
# 막대를 붙여넣기 할 Y 축 위치 지정
# db_ceiling 값에서 각 볼륨 크기 값을 뺀 만큼의 위치에 막대의 가장 위쪽 끝을 맞춰서 붙여넣기 한다. 가장 큰 막대는 전체 이미지의 제일 위에 딱 붙게 된다.
# offset_top 값을 더해주어 가장 큰 막대가 이미지의 가장 위로부터 4px 만큼 떨어지게 된다.
upper_endpoint = (self.db_ceiling - value) + offset_top
# 막대 넓이 값과 볼륨 크기 데이터의 두 배 값을 높이 값으로 전달해주어 막대를 생성한다.
# 생성한 막대를 column과 upper_endpoint를 각각 X, Y 좌표로 가지는 지점에 붙여넣기 한다.
im.paste(self._get_bar_image((bar_width, value * 2), '#333533'),
(column, upper_endpoint))
결과

Wavesurfer.js 로 만들었던 이미지와는 구현 로직이 다른지 좀 다른 이미지가 그려지긴 했지만 어쨋거나 그럴싸한 파형이 완성되었다.
색상 바꿔주기
이제 기본 오디오 파형 이미지가 그려졌으니 이것과 동일한 크기의 다른 색상인 파형 이미지가 필요하다.
기본 오디오 파형과 다른 색의 파형을 겹친 다음 색이 있는 이미지의 넓이 값을 동적으로 조절하여 음원 파일의 진행 상태를 표시하는 효과를 주기 위해서이다.
색상 바꾸기를 위해서 이번에도 Pillow 패키지를 사용한다.
참고자료: Stackoverflow
def change_color(base_png):
# 이미지 파일을 불러온다
im = Image.open(base_png)
newimdata = []
black1 = (51, 53, 51, 255)
yellow1 = (226, 176, 38, 255)
blank = (255, 255, 255, 0)
for color in im.getdata():
# 이미지를 순회하면서 색상이 (51, 53, 51, 255) 이면
if color == black1:
# (226, 176, 38, 255) 로 바꾼 값을 새 리스트에 저장
newimdata.append(yellow1)
else:
# 나머지는 (255, 255, 255, 0) 로 바꾸어 새 리스트에 저장
newimdata.append(blank)
# 원래 이미지의 mode 값과 size 값을 그대로 가져와 새 이미지를 생성
newim = Image.new(im.mode, im.size)
# 새 리스트의 데이터를 새 이미지에 입력
newim.putdata(newimdata)
# 이미지 저장 경로
# 파일 이름은 '원본파일이름_cover.png' 로 저장되도록 해주었다.
out_dir = base_png.replace('.' + base_png.split('.')[-1], '_cover.png')
# 주어진 경로에 이미지 저장
newim.save(out_dir)
return out_dir
위 함수에 이전에 만들었던 검은 파형 이미지 파일을 전달하면 아래와 같이 색상이 바뀐 이미지가 출력된다.

manage.py 에 커맨드 추가하기
이제 이미지를 생성하는 모든 과정이 서버에서 이루어지므로 이미 업로드 되어있는 음원들에 대해서도 이미지를 생성해줄 수 있게 되었다.
이것을 manage.py 의 명령어에 추가해주기로 했다.
먼저 Post 모델이 웨이브폼 이미지를 저장할 수 있도록 필드를 추가해주었다.
class Post(models.Model):
...
author_track_waveform_base = models.ImageField(
upload_to=author_track_waveform_base_directory_path, blank=True, null=True
)
author_track_waveform_cover = models.ImageField(
upload_to=author_track_waveform_cover_directory_path, blank=True, null=True
)
...
그리고 Post 앱 아래에 management 패키지를 추가하고 그 아래에 commands 패키지를 추가한 다음 그 아래에 createwaveform.py 모듈을 추가해주었다.
posts
├── management
│ ├── __init__.py
│ └── commands
│ ├── __init__.py
│ └── createwaveform.py
.
.
.
createwaveform.py 모듈은 아래와 같다.
from django.conf import settings
from django.core.files.base import ContentFile
from django.core.management.base import BaseCommand
from posts.models import Post
# 위의 파형 생성 및 색상 변경 메서드들이 들어있는 모듈
from utils.pywave import Waveform
class Command(BaseCommand):
help = 'Creates waveform image from an audio file source'
def handle(self, *args, **options):
# 모든 포스트 목록을 순회하면서 author_track 에 대한 파형 이미지를 생성함
# 생성한 이미지들을 각각 author_track_waveform_base, author_track_waveform_cover 필드에 업로드해준다.
posts = Post.objects.all()
for post in posts:
# 이미지를 생성할 로컬 경로
audio_dir = settings.ROOT_DIR + post.author_track.url
# 이미지 생성
waveform = Waveform(audio_dir)
# 기본 이미지 저장
waveform_base = waveform.save()
# 색상 변경한 이미지 저장
waveform_cover = waveform.change_color(waveform_base)
# 기본 이미지 열어서 장고 ContentFile로 변환
with open(waveform_base, 'rb') as f1:
base = ContentFile(f1.read())
# 색상 변경한 이미지 열어서 장고 ContentFile로 변환
with open(waveform_cover, 'rb') as f2:
cover = ContentFile(f2.read())
# 각 이미지를 post 객체의 필드에 업로드함
post.author_track_waveform_base.save('author_track.png', base)
post.author_track_waveform_cover.save('author_track_cover.png', cover)
# post 객체 변경사항 저장
post.save()
이렇게 해준 다음 ./manage.py createwaveform 명령을 실행하면 모든 Post 객체의 author_track 음원 파일에 대한 파형 이미지가 생성된 다음 필드값으로 업로드된다.
이어지는 포스트에서는 이 두 이미지를 가지고 인터렉티브 한 오디오 컨트롤러를 구현하는 방법에 대해 다루겠다.
Reference
파형 이미지 생성: waveformpy_mixxorz_python
파형 색상 변경: Stackoverflow